Why GPT Image 2 Images Feel More Useful for Creators
GPT Image 2 is getting attention because its images feel less like experiments and more like assets creators can actually use. It is not just about sharper details or prettier styles. The real upgrade is practical: clearer text, cleaner layouts, more consistent characters, polished product visuals, and stronger first frames for AI videos. For creators, that matters. A good AI image should not only look impressive for five seconds. It should be useful enough for a blog cover, thumbnail, social post, ad concept, or visual story. So what actually feels different in GPT Image 2? Let’s look at where it improves — and where it still feels like AI. Why GPT Image 2 Feels Different From Older AI Image Models Older AI image models could look impressive at first glance, but the flaws showed up quickly: broken text, messy layouts, inconsistent characters, and polished visuals that still felt artificial. GPT Image 2 feels different because it handles the practical side of image generation better. Posters look more readable, products are clearer, characters stay more recognizable, and visuals feel more purposeful. That is why creators are paying attention — it does not just make prettier images, but more usable ones. The Image Effects People Notice Most GPT Image 2 feels different because its improvements show up in places creators actually use. The results are not just prettier; they are easier to turn into thumbnails, covers, product visuals, story assets, and first frames for videos. Text in Images Looks Much More Readable Text is one of the clearest improvements. Older AI image models could create a strong poster background, then ruin it with broken letters, fake words, or unreadable symbols. That made the image hard to use for thumbnails, ads, product labels, menus, and social posts. GPT Image 2 handles short text better. Titles look cleaner, labels are easier to read, and simple poster copy feels more intentional. This matters because creator visuals often depend on just a few clear words: a YouTube thumbnail needs a hook, a TikTok cover needs a bold phrase, and a product mockup needs a label that does not look broken. Still, it is not perfect. Long text, prices, dates, brand names, small disclaimers, and non-English copy still need manual checking. Posters and Covers Feel More Designed GPT Image 2 also makes posters, covers, and promotional visuals feel more complete. Instead of placing random text over a nice background, it often creates a clearer relationship between the subject, title, spacing, lighting, and background. That makes it useful for blog covers, YouTube thumbnails, TikTok covers, product ads, campaign images, and social graphics. The key word is direction. GPT Image 2 can quickly help you explore a visual idea, but it does not replace real design files. A generated poster is still a flat image, not a layered Figma or Photoshop file. Characters Stay More Consistent Character consistency is another effect creators care about. If you are making a story, comic, mascot, or AI video, one good image is not enough. The character needs to stay recognizable across scenes. GPT Image 2 seems better at keeping the face, outfit, colors, and general style connected. This is useful for character references, storyboards, expression variations, and AI video first frames. A stronger first frame gives image-to-video tools a better starting point. Realistic Images Look More Polished GPT Image 2 can create clean, polished realistic images. Portraits, product mockups, lifestyle scenes, studio shots, and commercial visuals often look more refined and closer to usable brand material. But polished does not always mean natural. Some images still look too smooth, too controlled, or slightly artificial. For creators, the goal is not just to make an image look expensive. It should also feel believable. Structured Images Are More Useful One of the most useful changes is how GPT Image 2 handles structured visuals. These are images that explain something, such as comics, diagrams, product explainers, step-by-step graphics, maps, or before-and-after images. This matters because many creator visuals need to communicate quickly. GPT Image 2 seems better at organizing panels, labels, titles, and sections, but facts, numbers, and instructions still need review before publishing. Where GPT Image 2 Still Feels Like AI GPT Image 2 is more useful than older AI image models, but it still has limits. The problems usually appear when the image needs exact text, natural realism, or a less polished everyday look. Long Text Can Still Go Wrong Short titles and labels are much better, but long text is still risky. A poster with one bold headline may look clean, while a detailed infographic, product description, or paragraph can still include small mistakes. This matters for ads, product visuals, tutorials, and educational graphics. If the words are important, they should always be checked manually. Non-English Text Still Needs Checking Non-English text has improved, but it is not fully reliable. Chinese, Japanese, Korean, Arabic, and other languages may look visually convincing, but some characters or words can still be wrong. For multilingual creators, GPT Image 2 is useful for quick concepts, but final publishing still needs native-language review. Nature Scenes Can Look Too Synthetic Nature is harder than it looks. GPT Image 2 can create beautiful landscapes, but trees, clouds, mountains, grass, water, and sunlight may feel too sharp or too controlled. Sometimes every part of the image looks equally detailed, which makes the scene feel less natural. The result can be beautiful, but not always believable. Some Images Are Too Perfect Many GPT Image 2 images look clean, polished, and high-end. That works well for product concepts or commercial visuals, but it can feel fake for everyday content. Real photos often have small imperfections: uneven lighting, messy backgrounds, imperfect skin, or casual framing. If you want a more authentic result, ask for natural lighting, realistic imperfections, less polished textures, or casual photography instead of a luxury ad look. How to Use GPT Image 2 for Free You can use GPT Image 2 directly in ChatGPT. After the update, some users

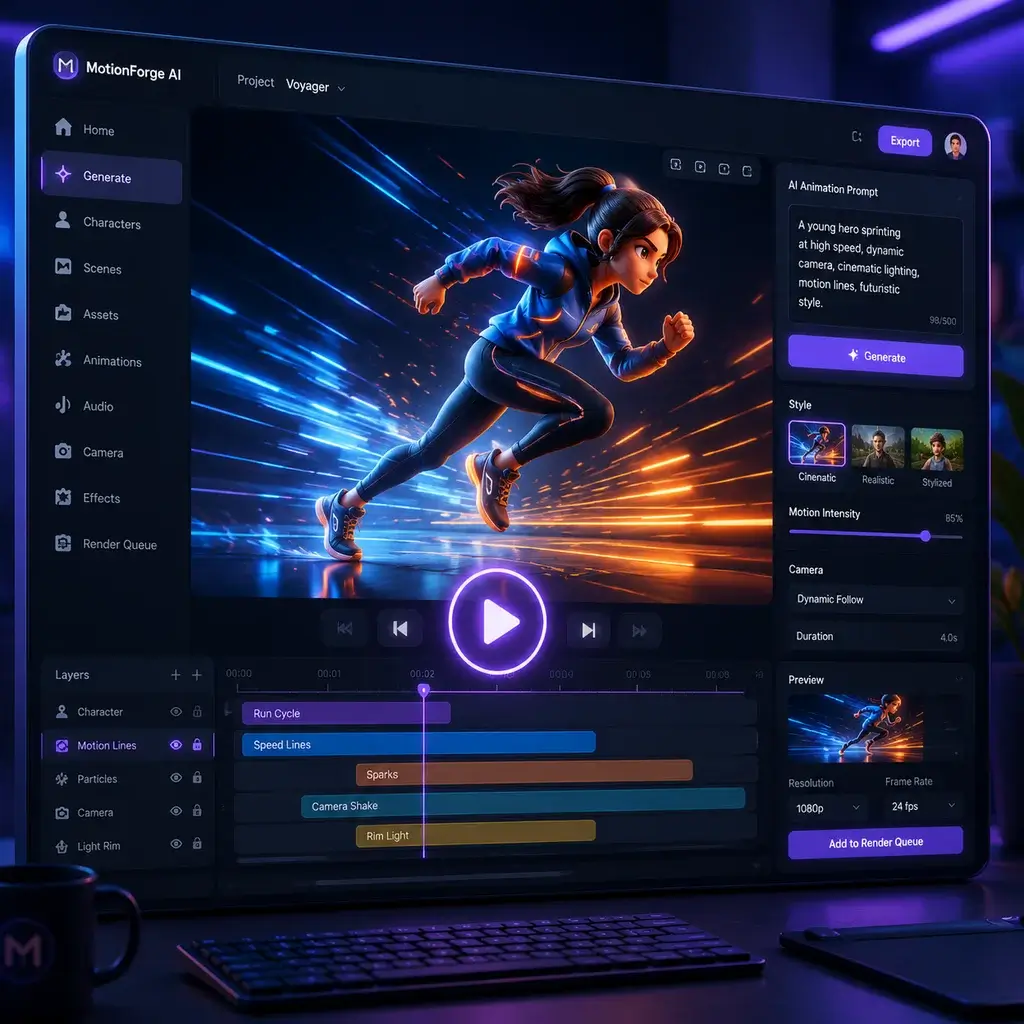


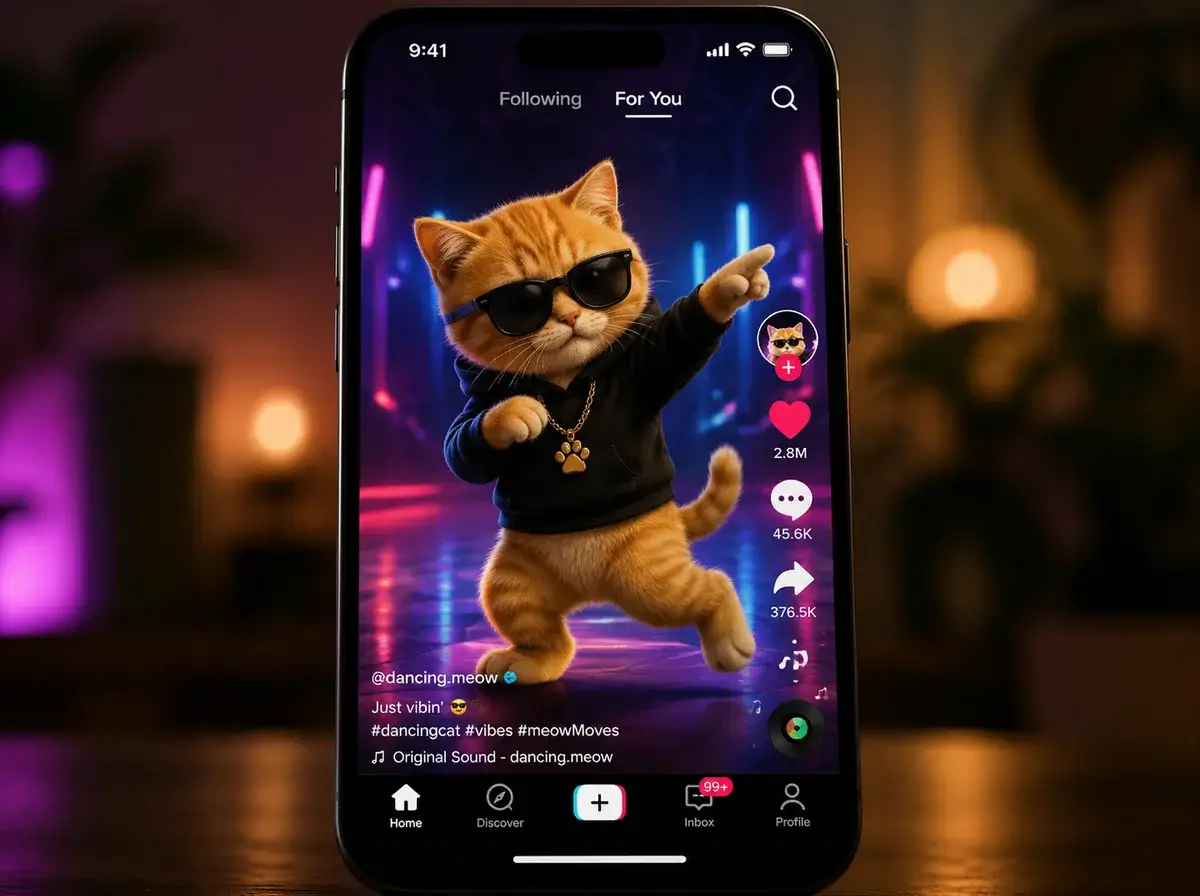












Amazing Seedance AI Free Experience
I wanted to use seedance free for my short film, and the seedance ai free tier on this platform was incredibly generous. The motion quality blew me away compared to other tools I have tried recently.
Better Than Seedance 1.5 Pro
Upgrading from seedance 1.5 pro was the best decision. The seedance cost is totally justified by the massive leap in rendering speed and facial expression accuracy. It handles complex character movements flawlessly.
Great Seedance 2.5 Animation Generation
The seedance 2.5 animation generation is phenomenal. Even with a low seedance price point here, the output quality rivals premium studio software. My 2D character animations look incredibly smooth and professional.
Easy to Use Seedance 2.5 Reddit Guide
After reading a how to use seedance 2.5 reddit thread, I tried this seedance video app alternative. The interface is much more intuitive, and I generated my first high-quality clip in under five minutes.
Perfect for Photo Dance AI Projects
I needed a reliable photo dance ai for a music video. The ability to make image dance to the beat was perfect. The rhythm synchronization and limb tracking are genuinely impressive for an automated tool.
Top Tier Chinese AI Art Generator
As a digital artist, this chinese ai art generator respects my original brushwork. The underlying chinese ai model understands artistic styles better than Western alternatives, keeping my illustrations intact while animating them.
Amazing Seedance AI Free Experience
I wanted to use seedance free for my short film, and the seedance ai free tier on this platform was incredibly generous. The motion quality blew me away compared to other tools I have tried recently.
Better Than Seedance 1.5 Pro
Upgrading from seedance 1.5 pro was the best decision. The seedance cost is totally justified by the massive leap in rendering speed and facial expression accuracy. It handles complex character movements flawlessly.
Great Seedance 2.5 Animation Generation
The seedance 2.5 animation generation is phenomenal. Even with a low seedance price point here, the output quality rivals premium studio software. My 2D character animations look incredibly smooth and professional.
Easy to Use Seedance 2.5 Reddit Guide
After reading a how to use seedance 2.5 reddit thread, I tried this seedance video app alternative. The interface is much more intuitive, and I generated my first high-quality clip in under five minutes.
Perfect for Photo Dance AI Projects
I needed a reliable photo dance ai for a music video. The ability to make image dance to the beat was perfect. The rhythm synchronization and limb tracking are genuinely impressive for an automated tool.
Top Tier Chinese AI Art Generator
As a digital artist, this chinese ai art generator respects my original brushwork. The underlying chinese ai model understands artistic styles better than Western alternatives, keeping my illustrations intact while animating them.